My goal for Cloudflare Markdown For Agents Monitoring
I enabled this a few weeks ago and started to log. I checked in on it this week (glad I did) and saw almost zero markdown hits except malware. I wanted to know whether any AI agents were actually requesting the markdown representation of the page, who they were, and how often - basically, is this worth keeping and optimizing, or is it a feature sitting there that nobody uses?
How I checked it even works
Instead of testing an existing source, I triangulated:
- Edge tests (curl): confirmed
Accept: text/markdownreturns markdown. - Origin logs (SSH, nginx): measured AI-bot crawl volume by user-agent.
- Origin direct test: proved the origin only ever serves HTML, so the markdown conversion is 100% Cloudflare's edge, not the server.
- Cloudflare GraphQL Analytics: pulled the real edge content-type split and per-bot behavior.
- AI Crawl Control dashboard: cross-checked the feature status and fulfillment.
- Made a Discord bot to remind me - because I tend to forget these experiments.
- I did not touch the server config - my network admin would kill me.
The feature works - and it is tiny
A GET with Accept: text/markdown returns content-type: text/markdown with a clean markdown body (YAML front-matter plus content), roughly 95% smaller than the HTML. AI Crawl Control reported "96% of markdown requests fulfilled."
What a markdown grab actually looks like
I wanted to see if what Cloudflare was outputting actually looked worthy of the page. I looked at a VDP (a vehicle page) because that is arguably the most important type of page on a car dealer. The highlights of what it grabbed:
- Title and description with the VIN baked into the description
- Basic info tables (Body: SUV, Mileage: 12,234, 21 hwy / 15 city MPG, Black/Black, 3.0L V6, ZF 8-speed)
- Full DESCRIPTION, DETAILS (the entire feature list - nav, harman/kardon, etc.), TERMS & CONDITIONS
- Price: $24,888.00, financing CTAs, VIN XYZ / STOCK MXYZ
- "Other vehicles you may like," full dealer NAP and hours
- It grabbed all the JSON-LD, which contains all the images of the car
- All of Yoast's output
Size: 23 KB markdown vs 369 KB HTML - about 16x smaller.
Does this actually matter for SEO?
WHO KNOWS?! Maybe, and to be honest, probably. If LLMs can spend 96% less to get the exact same data, why wouldn't they? If they don't now, they will soon. Some now, some later. My opinion, not facts.
Things I fixed and learned the hard way
- Vary: Accept was missing on HTML responses. Without it, caches can serve cached HTML to a markdown-negotiating client. Fixed with a Cloudflare Response Header Transform Rule (set static Vary = Accept-Encoding, Accept). This is what broke basically everything.
- Edge caching and markdown coexistence. Added a Cache Rule (HTML GET pages, 4h Edge TTL) that excludes
Accept: text/markdownand bots, so browsers get cached HTML (HIT) while agents still get freshly-converted markdown on the same URLs. I tested this several different ways. - The testing gotcha (this cost me a full hour):
curl -I(HEAD) returnstext/htmleven when the feature works, because HEAD has no body to convert. Always test with GET. A false "it broke" panic came entirely from using-I.
The one-week measurement I built
To get precise, ongoing data - not Cloudflare's sampled analytics - I deployed:
- A Cloudflare Worker (
md-agent-logger) onexample.com/*, a transparent passthrough that logs everyAccept: text/markdownGET to Workers Analytics Engine: agent UA and family, path, country, ASN/org, IP, datacenter, ray-id, response latency, status, timestamp. - A Discord digest on a 30-minute cron trigger that posts a summary only when there were hits (silent otherwise). Note: as I am writing this 30 minutes later, I am getting tons of hits already.
- A query script for on-demand reports (hits by agent/day/path, crawl-session spans, countries), excluding my own seed and test traffic.
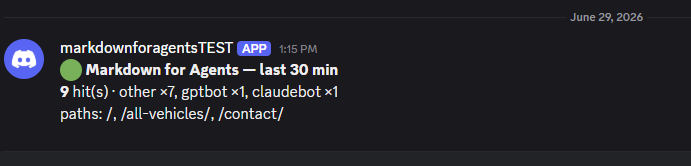
Verified end to end: log into Analytics Engine, cron query, Discord. The Worker does not disturb the markdown conversion - markdown still serves correctly with it live. I will tear it down after the week with npx wrangler delete (the data stays queryable for about 90 days).
Conclusions
Markdown for Agents is technically working and worth keeping - it is a forward-looking bet with basically zero downside. The one-week log will give me real adoption numbers to decide whether to invest further (cleaning up the markdown output, promoting llms.txt), or just leave it as is. My early read: the plumbing is real, but the agents you actually care about are not all using it yet. That is a reason to turn it on now and be ready, not a reason to expect fireworks in your analytics tomorrow.
I am going to update this post in a few weeks, or maybe less, once there is a nice chunk of data - which agents requested markdown, how often, and on which pages, measured straight off the edge instead of from a sampled dashboard. If you want to set this up on your own site in the meantime, the how-to guide is here.