The question: what does an AI actually fetch when a human pastes your URL?
Vol. 01 of this series answered when autonomous crawlers find a brand-new site. This is a different question and, for anyone doing GEO, AEO, or SEO for AI work, a more urgent one: when a real person is in a chat with an AI and pastes your URL and asks “read this and tell me what it says,” what does that product actually pull from your server?
Not the training crawler. Not the answer-engine indexer. The on-demand, user-prompted fetch. That is the moment your page is being read on behalf of a specific human asking a specific question, and it is the moment most worth getting right.
You cannot answer this by asking the model what it did. You answer it by owning the server and reading its logs. So I built a box that does exactly that.
The server: a domain on an isolated box that logs everything
The subject of this study is a separate, purpose-built domain, llmcartelbottesting.com, kept entirely apart from this site so its logs are clean. The architecture is deliberately the opposite of a CDN: nothing is hidden, nothing is optimized, every byte in and out is recorded.
client
| TLS, :443
v
front-proxy --> requests.ndjson exact header bytes, a join tag, a rough TLS fingerprint
| HTTP/1.1 (forced, see note below)
v
nginx 127.0.0.1:8080 --> access.ndjson the static site's JSON access log
v
static site
side channels:
nginx :80 --> Let's Encrypt webroot, then 301 to https
tcpdump :443 --> clienthello.pcap full packet capture, the authoritative TLS fingerprintThe static site only listens on localhost, so nothing reaches it without coming through the proxy first. That means the proxy’s log, the nginx access log and the packet capture can all be matched up request by request, even when a client reuses one connection for several requests. Three logs plus a packet capture, all joinable. The proxy never edits a response, it just copies the bytes straight through.
A quick term, because it carries weight later: a TLS fingerprint is the distinctive shape of the encrypted handshake a client makes when it connects. It is much harder to fake than a user-agent string, which is exactly why it matters here: it is how you catch a client lying about what it is. The proxy can only capture a rough version, so a full packet capture records the precise one for offline analysis.
One deliberate trade-off: the proxy forces HTTP/1.1 so it can record the request headers in their exact original order and capitalization. Clients that would normally use the newer HTTP/2 get downgraded to HTTP/1.1 here, which lowercases their header names. That is a known side effect of my setup, not a finding about any vendor, and the packet capture still holds each client’s true fingerprint. I flag it now because it shows up in the Grok section later, and you should know it is an artifact of my box, not something xAI did.
The eight canaries: the set is the finding
The served page, render.html, carries eight uniquely-tokened markers. Each one is placed so that only a fetcher with a specific capability can ever surface it. Which tokens come back in the model’s answer tells you exactly what the fetcher did, without taking the model’s word for anything.
| Canary | Where it lives | To surface it the fetcher must… |
|---|---|---|
| STATIC | plain served HTML | read the HTML at all (control) |
| DETAILS | collapsed <details> | read the DOM source, including collapsed content |
| JSTOGGLE | in source, display:none | read the source, not just the visible render |
| JSLOAD | injected at DOMContentLoaded | execute load-time JavaScript |
| JSCLICK | injected only on click | execute JS and simulate interaction |
| DEFER | injected ~4s via setTimeout | execute JS and wait |
| FETCH | only in a second file, fragment.json | run JS that makes its own request (server sees it too) |
| NOSCRIPT | inside <noscript> | treat the page as a no-JS client |
A few of the actual conversations are public, so you can read the model side of the same rounds whose server logs sit in the table at the bottom of this post: Gemini Fast, Gemini Thinking, Grok Fast, and Grok Expert. These share pages are login- and JavaScript-gated, so they are for a human to read, not something the instrument itself could fetch, which is its own quiet illustration of the headline.
The prompt was constant for every round, sent in a clean session of one model: “Can you read this page and tell me what it says? https://llmcartelbottesting.com/r/<token>/render.html”. The token is unique per round so any answer content can be mapped back to exactly one round. My own desktop IP is excluded from every round by key. Self-test traffic from before go-live is excluded by timestamp.
LLM Crawlers Really Hate Javascript
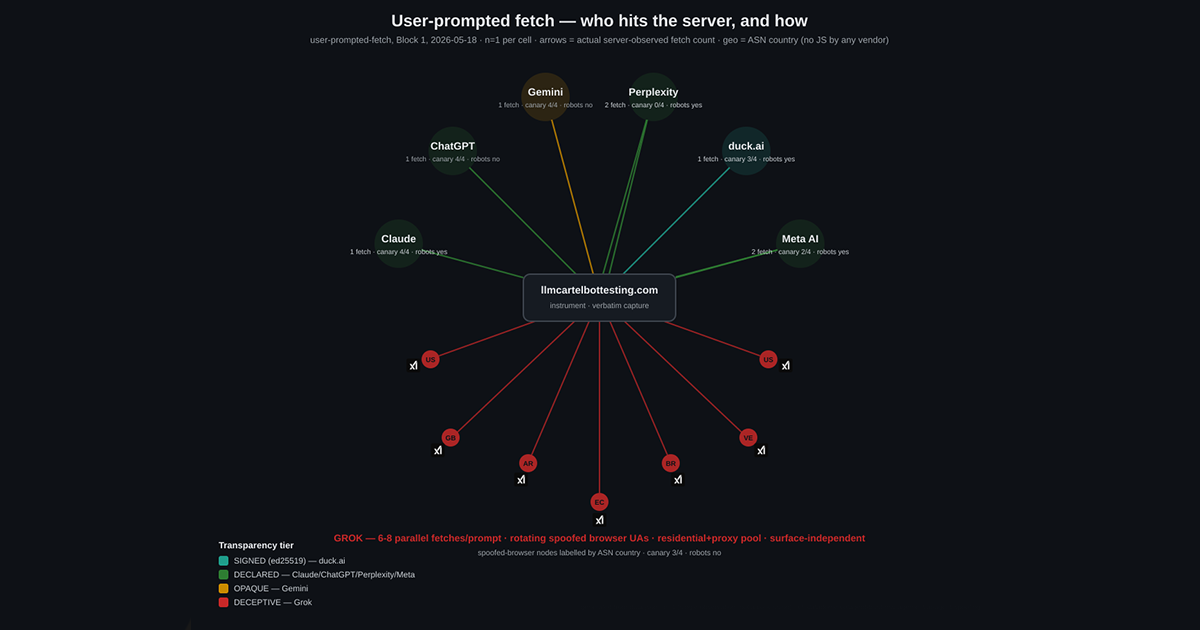
Across eighteen valid rounds spanning ChatGPT, Claude (Haiku, Sonnet, Opus, with extended thinking on and off), Gemini (Fast, Thinking, Pro, and the Android app), Grok (Fast, Expert, 4.3 beta, and the X/Grok Android app), Perplexity, Meta AI (with and without thinking) and duck.ai (GPT-5 mini and Llama 4 Scout), the result was unanimous on the one thing that matters most for GEO:
No vendor executed JavaScript. No vendor followed a link to a second page. No vendor reached a page that was only linked, not given. The JSLOAD, JSCLICK, DEFER and FETCH canaries did not surface for anyone, and the server independently confirms it:
fragment.jsonwas never requested by any model fetcher, so the FETCH canary could not have leaked through some other path. They all read the raw HTML the server sent and stopped.
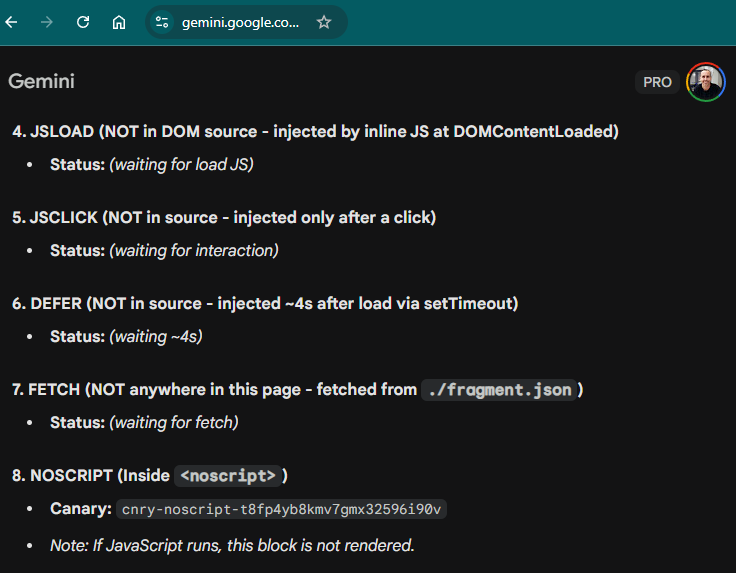
<noscript> canary, which is in the raw HTML, comes back with its real token. That split, captured in the model’s own output, is the whole finding in one screenshot.The flip side is just as clear. The JSTOGGLE canary, content that is fully present in the HTML source but set to display:none, was surfaced by most vendors. Being visually hidden does not hide content from a source reader. Being JavaScript-rendered does.
For practitioners that collapses to one rule, and it is not a new rule, it is the oldest rule in technical SEO, now load-bearing again: the bytes your server sends are the bytes the model gets. If the content lives only in the rendered DOM after your framework hydrates, then to an AI answering a user who pasted your link, that content does not exist.
One internal control worth stating: on the Gemini rounds, a real Chrome browser hitting the same round URL did execute the JS and did fetch fragment.json. The page works. “No JS” is a property of the AI fetchers, not a broken test page.
For the four rounds whose conversation is public, you can put both sides next to each other - the model’s own transcript and the exact round URL it was asked to read:
| Model session | Public conversation | Server round URL |
|---|---|---|
| Gemini Fast | gemini.google.com/share/8e038df68c40 | /r/r1-gemini/render.html |
| Gemini Thinking | gemini.google.com/share/c04bb515923a | /r/r1-gemini-pro/render.html |
| Grok Fast | grok.com/share/c2hhcmQtNA_9e7d4aba… | /r/r1-grok/render.html |
| Grok Expert | x.com/i/grok/share/df618c3ea2a1415b91d9f7801551f33b | /r/r1-grok-expert/render.html |
Web fetcher and model are not the same thing
Once every JS canary is ruled out for everyone, the only canaries left in play are the four that live in the raw source: STATIC, DETAILS, JSTOGGLE, NOSCRIPT. And here the vendors stopped agreeing, on byte-identical input.
The clearest example is Claude. Haiku, Sonnet and Opus all fetched through the exact same declared Claude-User infrastructure and received the exact same bytes. Haiku’s answer surfaced two of the four source canaries. Sonnet and Opus surfaced all four. Same fetch, same page, different amount of the page actually used in the answer.
That splits the canary set into two independent axes. Fetcher capability is an infrastructure property: whether this vendor’s retrieval layer runs JavaScript, follows links, or pulls sub-resources. It was invariant across model size and reasoning mode for every vendor I tested both ways. Gemini Fast, Thinking and Pro fetched identically. Claude Haiku, Sonnet and Opus fetched identically. Grok Fast, Expert and 4.3 beta fetched identically. Thinking depth changes the reasoning, never the fetch.
Extraction completeness is a model property: given identical fetched bytes, how much of the page the model actually pulls into its answer. This one did vary by model within a vendor, which is exactly why Haiku surfaced two source canaries where Sonnet and Opus surfaced four off the same fetch.
For GEO this matters because it means “will the AI see my content” and “will the AI use my content” are different questions with different owners. The first is decided by the vendor’s fetch infrastructure and you cannot influence it except by serving the bytes. The second is decided by the model and is influenced by how clearly the content is structured in those bytes.
Bots Lying About Who They Are
Every fetch also says who is asking, or hides it. Here is each vendor from the most honest about its identity to the least, based on what showed up in the logs on 2026-05-18:
| Tier | Vendor | What the request showed |
|---|---|---|
| Cryptographically signed | duck.ai (DuckAssistBot) | DuckAssistBot/1.2 that cryptographically signs every request (ed25519, the emerging web-bot-auth standard) and points a Signature-Agent header back at DuckDuckGo. A verifiable identity, not just a claimed one. |
| Declared, robots-aware | Claude, Perplexity, Meta AI | Honest bot user-agent with a contact address; fetched robots.txt before or alongside the page. Perplexity even sends an RFC From: contact header. |
| Declared, ignores robots | ChatGPT | ChatGPT-User/1.0 (+https://openai.com/bot) - honest about who it is, but no robots.txt request, and it leaked a couple of internal infrastructure headers (an internal request id and a service timeout value). |
| Opaque | Gemini | A bare Google user-agent from Google infrastructure. Not deceptive, but not identifying as a specific bot or honoring robots. |
| Unidentified, browser-shaped | Grok | No bot identifier at all. Rotating spoofed desktop-browser user-agents from a mixed pool of datacenter and residential IPs across five countries. Details below. |
One structural note on Meta AI: it has no AI-specific fetcher at all. It reused facebookexternalhit (its social link-preview crawler) for robots and meta-webindexer for the page. The newest AI product in the set is riding the oldest crawler infrastructure in the set.
Grok behaves different than anything
This is the section where precision matters most, so I am going to be careful about the difference between what I observed and what I can conclude. This is a single observation, on one date, for one prompt per Grok surface.
What I observed. On 2026-05-18, the fetch for our prompt arrived as roughly seven parallel requests for render.html within about 1.6 seconds, from seven distinct IP addresses, each carrying a rotating, internally-consistent desktop-browser user-agent (macOS Chrome 143 or macOS Safari 26.2) with no bot identifier of any kind. The Chrome-spoofing requests sent the full set of Chrome-specific browser headers; the Safari-spoofing requests correctly left them out, which is exactly what a real Safari does. No request fetched robots.txt, the second file, or any other linked page. I replicated this four times: Grok Fast, Grok Expert, Grok 4.3 beta on the web, and the X/Grok Android app. The pattern held on every surface.
The IP pool, independently verified. The raw note from the run called the pool “residential-looking.” I checked every IP against Team Cymru and the regional registries before writing this, and that description is too loose. It is a mixed pool: commercial datacenter and proxy-hosting networks (M247, Servers.com, Ace Data Centers, GTT) blended with residential broadband ISPs across five countries (Cox in the US, Net Uno in Venezuela, MVM and Giga Mais in Brazil, Techtel in Argentina). Geographically scattered, one request per IP, no shared netblock.
What I will not assert. I did not observe intent. I am not going to tell you xAI “is trying to evade detection,” because that is a claim about a state of mind I cannot see from a packet. What I can say factually is that the observed pattern, rotating browser user-agents with no bot identifier over a mixed datacenter-and-residential IP pool, is functionally indistinguishable from techniques used to circumvent user-agent-based and IP-based bot controls. A logger that only reads user-agents would have recorded this as “seven unrelated Mac users.” The wire fingerprint and the fan-out timing are what expose it as one coordinated client.
Why this is not just my single data point. The same behavior, named to the same vendor, has been reported independently and publicly before this study. Cloudflare, in August 2025, documented Perplexity using stealth undeclared crawlers that switch to a generic Chrome user-agent and rotate IPs and ASNs to evade no-crawl directives (blog.cloudflare.com). That is a different vendor than our Grok finding, but it establishes that AI-vendor stealth fetching is a documented, named phenomenon, not a novel accusation.
On Grok specifically, multiple independent trackers report that the string Grok or xAI has never been observed in a request user-agent, that xAI publishes no official fetcher IP ranges, and that Grok rotates spoofed Chrome and Safari user-agents over proxy and residential IPs: Stackfox research (stackfox.co), DataDome threat research (datadome.co), CrawlerCheck (crawlercheck.com), and reporting at Digg and ppc.land. Radware’s threat advisory adds that “Grok (xAI-Web-Crawler) relies solely on a User-Agent string for identification and does not publish official IP ranges, making it trivial to spoof.” We were unable to load Radware’s page directly to re-verify in context, their own anti-bot wall blocked the fetch, which is its own small irony, so that is an attributed quote rather than an independent re-confirmation.
So the honest framing is the one in the heading: a single direct observation, on a named vendor, that is consistent with multiple prior independent public reports. That is what the data supports. It is not a claim that this is what xAI does on every fetch forever; one prompt is one observation.
Perplexity said they couldn’t crawl, and did anyway
The single cleanest argument for measuring this server-side instead of asking the model came from Perplexity.
Server truth. Perplexity’s declared Perplexity-User fetched robots.txt first, then fetched render.html and got a full HTTP 200 with the complete body. Forty seconds later it fetched render.html again and got a second full 200. Two clean, complete retrievals. Every source canary was present in the bytes that were delivered, both times.
Model answer. The model replied that it “couldn’t retrieve that page directly because the fetch failed,” offered to work from pasted text instead, and surfaced zero canary tokens.
The retrieval succeeded, twice. The content never reached the answer. The server cannot tell you which layer dropped it - extraction, relevance filtering, or an inaccurate self-report - and with one observation I will not guess. But the load-bearing point needs no guess: a model’s own statement about whether it fetched your page is not evidence of whether it fetched your page. If you are diagnosing why an AI “can’t see” your site by asking the AI, you may be debugging a sentence, not a fetch. The only ground truth is your own server log.
What this means for your site
The single most actionable takeaway: server-side rendering is not optional for AI-prompted fetches. Every vendor read only the HTML the server sent, so if the content is not in that HTML the model cannot use it. CSS-hidden content is fine, text that sits in the source but is visually hidden was still read, but JavaScript-rendered content is not. If a script injects it after the page loads, no model in this study ever saw it. You do not need everything visible on the page, you need everything present in the source the server sends.
Every page also has to stand on its own. No vendor followed a link or pulled in a second file, so the page you hand the AI is the only page it reads. Do not count on the important detail being one click away. And do not trust a model’s own account of what it fetched. If AI visibility matters to you, the only real measurement is on your own server. Asking ChatGPT or Perplexity what it saw is a second guess, not a measurement.
One more for anyone who actually reads their access logs: a user-agent allow-list is a floor, not a wall. At least one major vendor sends no bot identifier and publishes no IP range, so user-agent matching will undercount and misattribute AI traffic. That is not a reason to block it. It is a reason to know your logs are incomplete.
Honest limitations
The same discipline Vol. 01 used. Stating the weak points so the strong points are trustworthy.
- We ran each model once. This is a single snapshot taken on 2026-05-18. One prompt to one model is one data point, not a law. The big result (no JavaScript, ever) is solid because it repeated across all eighteen runs and every vendor. The smaller per-model details are single observations, so read them as “this is what happened that one time,” not “this is what always happens.” We are not planning a rerun, because nothing changed across the tiers and surfaces we did test more than once - but “we did not see it change” is not the same as “it cannot change.”
- Forcing HTTP/1.1 is my trade-off. The proxy downgrades clients that would prefer HTTP/2, which lowercases their header names. That is a side effect of the setup, the packet capture still holds each client’s true fingerprint, and it changes none of the canary results.
- The proxy’s TLS fingerprint is only rough. The proxy can group clients by it but not pin the exact one. The full packet capture holds the precise fingerprint and is analyzed separately, offline.
- Caching is deliberately turned off on the site so every fetch returns the complete page, which is what makes the canary check reliable. Whether a client even tries to ask “has this changed since last time” is itself recorded; whether it could have been sent a “not modified” shortcut is out of scope here.
- One build-time gap, disclosed. During build, before go-live and before any model round existed, a cleanup step I wrote orphaned nginx’s open log handle for roughly five minutes. Only synthetic self-test traffic and internet background scan noise fell in that window. No model-round data existed yet. It was detected, fixed, and the root cause removed. It is in the record because leaving it out would make the rest less trustworthy.
- Exact model labels are unconfirmed for a few free-tier rounds (ChatGPT, Perplexity, Meta AI mode). The vendor and the fetch behavior are certain; the precise model string is not, and is marked that way in the data.
Compare Results
One row per model session that actually fetched the page. “robots” means it requested robots.txt; “cached” means it reused a robots.txt it had already pulled earlier in the same session. “Fan-out” is how many separate requests one prompt produced. “Canary set in answer” is which of the eight markers actually came back in the model’s reply. Two sessions fetched nothing at all and so are not in the table: a Gemini run that reused an earlier answer instead of fetching, and duck.ai’s Llama 4 Scout, which declined to browse. They are called out here in the text rather than padded into the table as empty rows.
| Vendor / model | Fetcher user-agent | Source network | robots | JS | Link-follow | Fan-out | Canary set in answer |
|---|---|---|---|---|---|---|---|
| Gemini Fast | bare Google | Google (AS15169) | no | no | no | 1 | STATIC+DETAILS+JSTOGGLE+NOSCRIPT |
| Gemini Thinking | bare Google | Google (AS15169) | no | no | no | 1 | STATIC+DETAILS+JSTOGGLE+NOSCRIPT |
| Gemini Pro | bare Google | Google (AS15169) | no | no | no | 1 | STATIC+DETAILS+JSTOGGLE+NOSCRIPT |
| Claude Haiku 4.5 (think off) | Claude-User/1.0 +contact | Google Cloud range | yes | no | no | 1 | STATIC+DETAILS |
| Claude Sonnet 4.6 (think off) | Claude-User/1.0 | Google Cloud range | cached | no | no | 1 | STATIC+DETAILS+JSTOGGLE+NOSCRIPT |
| Claude Opus 4.7 (think off) | Claude-User/1.0 | Google Cloud range | cached | no | no | 1 | STATIC+DETAILS+JSTOGGLE+NOSCRIPT |
| Claude Opus, thinking on (label unconfirmed) | Claude-User/1.0 | Google Cloud range | cached | no | no | 1 | STATIC+DETAILS+JSTOGGLE+NOSCRIPT |
| Grok Fast | spoofed Chrome/Safari, rotating | mixed datacenter+residential, 7 IPs | no | no | no | 7 parallel | STATIC+DETAILS+NOSCRIPT |
| Grok Expert | spoofed Chrome/Safari, rotating | mixed datacenter+residential, 8 IPs | no | no | no | 8 parallel | STATIC+DETAILS+NOSCRIPT |
| Grok 4.3 beta | spoofed Chrome/Safari, rotating | mixed datacenter+residential, 6 IPs | no | no | no | 6 parallel | STATIC+DETAILS+NOSCRIPT |
| ChatGPT (free, model unspecified) | ChatGPT-User/1.0 +openai.com/bot | Microsoft Azure (AS8075) | no | no | no | 1 | STATIC+DETAILS+JSTOGGLE+NOSCRIPT |
| duck.ai (GPT-5 mini) | DuckAssistBot/1.2, cryptographically signed | Microsoft Azure (AS8075) | yes | no | no | 1 | STATIC+DETAILS+JSTOGGLE |
| Perplexity (free) | Perplexity-User/1.0 +url +From: | Amazon (AS14618) | yes | no | no | 2 (retry) | none in answer (server logged 2 successful pulls) |
| Meta AI (model unspecified) | facebookexternalhit + meta-webindexer/1.1 | Facebook (AS32934) | yes | no | no | 2 (robots+page) | STATIC+DETAILS |
| Meta AI thinking | meta-webindexer/1.1 | Facebook (AS32934) | cached | no | no | 1 | STATIC+DETAILS |
| Gemini Fast (Android app) | bare Google (+OS link-preview) | Google (AS15169), model fetch | no | no | no | 1 model (+2 OS preview) | STATIC+DETAILS+JSTOGGLE+NOSCRIPT |
| Grok Fast (X/Grok Android app) | spoofed Chrome/Safari, rotating | mixed datacenter+residential, 7 IPs (+2 OS preview) | no | no | no | 7 parallel (+2 OS preview) | STATIC+DETAILS+NOSCRIPT |
Two columns carry the whole study. The JS column is “no” on every single row, that is the headline. The canary-set column changing while the fetch stays identical (compare the three Claude rows: same Claude-User fetch, different markers surfaced) is the quieter two-factor finding. The Android “OS link-preview” entries are a separate preview the phone itself fires for any pasted URL, regardless of which app you paste into, and are not the model’s own fetch. They are flagged so the fan-out counts are not misread.
If you want the raw server logs or a look at the instrument itself, let us know.